How do I start the yarn in Hadoop
Start YARN with the script: start-yarn.sh.Check that everything is running with the jps command. In addition to the previous HDFS daemon, you should see a ResourceManager on node-master, and a NodeManager on node1 and node2.To stop YARN, run the following command on node-master: stop-yarn.sh.
How do I start a YARN service?
- Manually clear the ResourceManager state store. …
- Start the ResourceManager on all your ResourceManager hosts. …
- Start the TimelineServer on your TimelineServer host. …
- Start the NodeManager on all your NodeManager hosts.
What is YARN commands?
YARN commands are invoked by the bin/yarn script. Running the yarn script without any arguments prints the description for all commands. Usage: yarn [SHELL_OPTIONS] COMMAND [GENERIC_OPTIONS] [SUB_COMMAND] [COMMAND_OPTIONS]
How does YARN work in Hadoop?
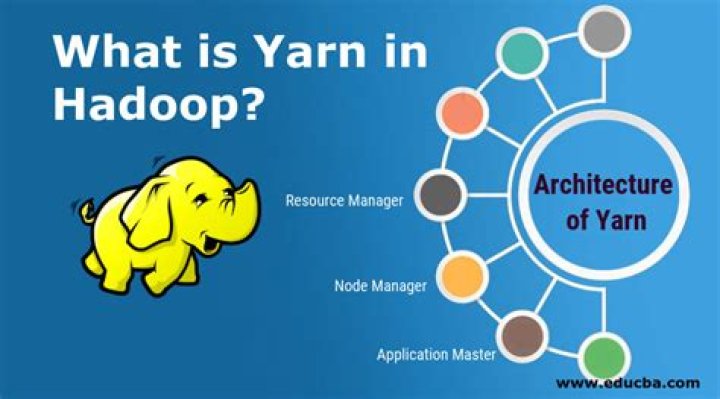
YARN is the main component of Hadoop v2. 0. YARN helps to open up Hadoop by allowing to process and run data for batch processing, stream processing, interactive processing and graph processing which are stored in HDFS. … In the YARN architecture, the processing layer is separated from the resource management layer.How do I start a Hadoop cluster?
- start-all.sh & stop-all.sh Which say it’s deprecated use start-dfs.sh & start-yarn.sh.
- start-dfs.sh, stop-dfs.sh and start-yarn.sh, stop-yarn.sh.
- hadoop-daemon.sh namenode/datanode and yarn-deamon.sh resourcemanager.
Where do you run yarn commands?
yarn init: we used this command in our tutorial on getting started, this command is to be run in your terminal. It will initialize the development of a package. yarn install: this command will install all the dependencies that is defined in a package. json file.
How do you restart the start of yarn?
- Stop the service by running the following command: sudo stop hadoop-yarn-resourcemanager.
- Wait a few seconds, then start the service by running the following command: sudo start hadoop-yarn-resourcemanager.
How do you create a YARN queue?
- Click Views on the Manage Ambari page.
- Click CAPACITY-SCHEDULER.
- Click the applicable YARN Queue Manager view instance, then click Go to instance at the top of the page. The queue will be added under the top-level, or root queue. A default queue already exists under the root queue.
How do YARN works?
YARN keeps track of two resources on the cluster, vcores and memory. The NodeManager on each host keeps track of the local host’s resources, and the ResourceManager keeps track of the cluster’s total. A container in YARN holds resources on the cluster.
What is YARN tool?Introducing Yarn. Yarn is a new package manager that replaces the existing workflow for the npm client or other package managers while remaining compatible with the npm registry. It has the same feature set as existing workflows while operating faster, more securely, and more reliably.
Article first time published onHow do you add yarn?
When you want to use another package, you first need to add it to your dependencies. This means running yarn add [package-name] to install it into your project. This will also update your package.
How do I start Hadoop in terminal?
Run the command % $HADOOP_INSTALL/hadoop/bin/start-dfs.sh on the node you want the Namenode to run on. This will bring up HDFS with the Namenode running on the machine you ran the command on and Datanodes on the machines listed in the slaves file mentioned above.
How do I start Hadoop in Linux?
- Install OpenJDK on Ubuntu.
- Set Up a Non-Root User for Hadoop Environment. Install OpenSSH on Ubuntu. …
- Download and Install Hadoop on Ubuntu.
- Single Node Hadoop Deployment (Pseudo-Distributed Mode) Configure Hadoop Environment Variables (bashrc) …
- Format HDFS NameNode.
- Start Hadoop Cluster.
- Access Hadoop UI from Browser.
How do I start Hadoop all services in one go?
- start-all.sh & stop-all.sh. Used to start and stop Hadoop daemons all at once. …
- start-dfs.sh, stop-dfs.sh and start-yarn.sh, stop-yarn.sh. …
- hadoop-daemon.sh namenode/datanode and yarn-deamon.sh resourcemanager. …
- Note : You should have ssh enabled if you want to start all the daemons on all the nodes from one machine.
How do you stop yarn?
- Step 2 – Pull out the yarn outside.
- Step 3 – Find the yarn end in the bunch of yarn that you pulled out and start you crocheting keeping the label on the whole time.
How do I start yarn in Windows?
- Open a new terminal. Click “Terminal” → “New Terminal” Simply use ctrl + shift + ` (backtick) …
- Once the Terminal is active, install Yarn by running npm install -g yarn .
- Verify the installation was successful by running yarn –version .
What is YARN and MapReduce?
YARN is a generic platform to run any distributed application, Map Reduce version 2 is the distributed application which runs on top of YARN, Whereas map reduce is processing unit of Hadoop component, it process data in parallel in the distributed environment.
What is YARN in Hadoop Cloudera?
YARN, the Hadoop operating system, enables you to manage resources and schedule jobs in Hadoop. YARN allows you to use various data processing engines for batch, interactive, and real-time stream processing of data stored in HDFS (Hadoop Distributed File System).
What is the use of YARN in Hadoop Mcq?
Explanation: YARN is the prerequisite for Enterprise Hadoop, providing resource management and a central platform to deliver consistent operations, security, and data governance tools across Hadoop clusters.
What is yarn queue in Hadoop?
The Yarn Capacity Scheduler allows for multiple tenants in an HDP cluster to share compute resources according to configurable workload management policies. The YARN Queue Manager View is designed to help Hadoop operators configure these policies for YARN.
How do I set the yarn queue in spark?
You can control which queue to use while starting spark shell by command line option –queue. If you do not have access to submit jobs to provided queue then spark shell initialization will fail. Similarly, you can specify other resources such number of executors, memory and cores for each executor on command line.
What is yarn queue?
Setting up Queues The fundamental unit of scheduling in YARN is a queue. The capacity of each queue specifies the percentage of cluster resources that are available for applications submitted to the queue.
How do I use yarn in Linux?
- Step 1: Configure the Yarn Repository. Open a terminal window, and add the GPG key: curl -sS | sudo apt-key add – …
- Step 2: Install Yarn. Update your local repository listings: sudo apt-get update.
What is yarn answer?
Explanation: Yarn is a long, continuous length of fibers that have been spun or felted together. Yarn is used to make cloth by knitting, crocheting or weaving. Yarn is sold in the shape called a skein to prevent the yarn from becoming tangled or knotted.
How do I add yarn to my path?
- set yarn prefix: make sure your yarn prefix is the parent directory of your bin directory. …
- add the following to ~/.bash_profile or ~/.bashrc export PATH=”$PATH:`yarn global bin`” for zsh users, be sure to add this line to ~/.zshrc.
- restart your shell or start a new one. bash -l or zsh.
How do I start Hadoop on Windows 10?
- Step 1 – Download Hadoop binary package. …
- Step 2 – Unpack the package. …
- Step 3 – Install Hadoop native IO binary. …
- Step 4 – (Optional) Java JDK installation. …
- Step 5 – Configure environment variables. …
- Step 6 – Configure Hadoop. …
- Step 7 – Initialise HDFS & bug fix.
How do I start and stop Hadoop services?
- Power on the Ambari Server or Virtual Machine if it was powered down.
- Log into the Ambari server by an ssh terminal session as the root user.
- Run the following command: systemctl start postgresql. …
- Verify that the PostgreSQL database service has stopped: systemctl status postgresq.
What is start DFS sh?
Inside the directory Hadoop, there will be a folder ‘sbin’, where there will be several files like start-all.sh, stop-all.sh, start-dfs.sh, stop-dfs.sh, hadoop-daemons.sh, yarn-daemons.sh, etc. … start-all.sh & stop-all.sh: Used to start and stop hadoop daemons all at once.
What is spark vs Hadoop?
Apache Hadoop and Apache Spark are both open-source frameworks for big data processing with some key differences. Hadoop uses the MapReduce to process data, while Spark uses resilient distributed datasets (RDDs).
How do I access Hadoop UI?
- Format the filesystem: $ bin/hdfs namenode -format.
- Start NameNode daemon and DataNode daemon: $ sbin/start-dfs.sh.
How do I run a MapReduce program in Hadoop?
- Now for exporting the jar part, you should do this:
- Now, browse to where you want to save the jar file. Step 2: Copy the dataset to the hdfs using the below command: hadoop fs -put wordcountproblem …
- Step 4: Execute the MapReduce code: …
- Step 8: Check the output directory for your output.