How does attention model work
Attention is proposed as a method to both align and translate. … — Neural Machine Translation by Jointly Learning to Align and Translate, 2015. Instead of encoding the input sequence into a single fixed context vector, the attention model develops a context vector that is filtered specifically for each output time step.
How does attention network work?
Attention takes two sentences, turns them into a matrix where the words of one sentence form the columns, and the words of another sentence form the rows, and then it makes matches, identifying relevant context. This is very useful in machine translation.
How does attention work in NLP?
The attention mechanism is a part of a neural architecture that enables to dynamically highlight relevant features of the input data, which, in NLP, is typically a sequence of textual elements. It can be applied directly to the raw input or to its higher level representation.
What is an attention based model?
Attention-based models belong to a class of models commonly called sequence-to-sequence models. The aim of these models, as name suggests, it to produce an output sequence given an input sequence which are, in general, of different lengths.How does attention work in neural networks?
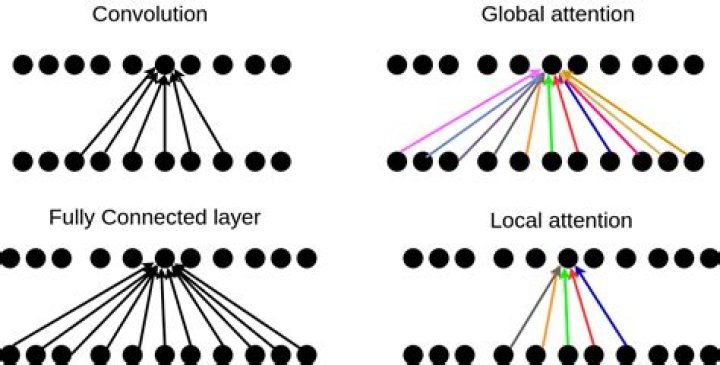
In neural networks, attention is a technique that mimics cognitive attention. The effect enhances some parts of the input data while diminishing other parts — the thought being that the network should devote more focus to that small but important part of the data.
What is attention used for?
Attention plays a critical role in almost every area of life including school, work, and relationships. It allows people to focus on information in order to create memories. It also allows people to avoid distractions so that they can focus on and complete specific tasks.
How is attention trained?
The attention mechanism was born to help memorize long source sentences in neural machine translation (NMT). Rather than building a single context vector out of the encoder’s last hidden state, the secret sauce invented by attention is to create shortcuts between the context vector and the entire source input.
Why is attention deep learning?
Deep Learning models are generally considered as black boxes, meaning that they do not have the ability to explain their outputs. However, Attention is one of the successful methods that helps to make our model interpretable and explain why it does what it does.How is attention calculated?
The attention weights are calculated by normalizing the output score of a feed-forward neural network described by the function that captures the alignment between input at j and output at i.
Why does self-attention work?A self-attention module works by comparing every word in the sentence to every other word in the sentence, including itself, and reweighing the word embeddings of each word to include contextual relevance. It takes in n word embeddings without context and returns n word embeddings with contextual information.
Article first time published onWhat is attention gate?
We propose a novel attention gate (AG) model for medical imaging that automatically learns to focus on target structures of varying shapes and sizes. Models trained with AGs implicitly learn to suppress irrelevant regions in an input image while highlighting salient features useful for a specific task.
What is soft attention?
Hard vs Soft attention in their paper, soft attention is when we calculate the context vector as a weighted sum of the encoder hidden states as we had seen in the figures above. Hard attention is when, instead of weighted average of all hidden states, we use attention scores to select a single hidden state.
Why do I have multiple attention heads?
Multi-head Attention is a module for attention mechanisms which runs through an attention mechanism several times in parallel. … Intuitively, multiple attention heads allows for attending to parts of the sequence differently (e.g. longer-term dependencies versus shorter-term dependencies).
What is attention module?
A Spatial Attention Module is a module for spatial attention in convolutional neural networks. It generates a spatial attention map by utilizing the inter-spatial relationship of features.
What is the process of attention?
Attention is the behavioral and cognitive process of selectively concentrating on a discrete aspect of information, whether considered subjective or objective, while ignoring other perceivable information.
What are the four types of attention?
There are four different types of attention: selective, or a focus on one thing at a time; divided, or a focus on two events at once; sustained, or a focus for a long period of time; and executive, or a focus on completing steps to achieve a goal.
What is attention based on?
Attention is arguably one of the most powerful concepts in the deep learning field nowadays. It is based on a common-sensical intuition that we “attend to” a certain part when processing a large amount of information.
What is attention map?
attention map: a scalar matrix representing the relative importance of layer activations at different 2D spatial locations with respect to the target task. i.e., an attention map is a grid of numbers that indicates what 2D locations are important for a task.
How do you use attention?
Examples of attention in a Sentence We focused our attention on this particular poem. My attention wasn’t really on the game. You need to pay more attention in school. She likes all the attention she is getting from the media.
What is Self-attention theory?
Self-attention theory (Carver, 1979, 1984; Carver & Scheier, 1981; Duval & Wicklund, 1972; Mullen, 1983) is concerned with self-regulation processes that occur as a result of becoming the figure of one’s attentional focus.
What is 3D UNet?
3D-UNet is composed of a contractive and an expanding path, that aims at building a bottleneck in its centermost part through a combination of convolution and pooling operations. After this bottleneck, the image is reconstructed through a combination of convolutions and upsampling.
What is UNet deep learning?
U-Net is a convolutional neural network that was developed for biomedical image segmentation at the Computer Science Department of the University of Freiburg. … Segmentation of a 512 × 512 image takes less than a second on a modern GPU.
How do you implement attention in keras?
- Step 1: Import the Dataset.
- Step 2: Preprocess the Dataset.
- Step 3: Prepare the Dataset.
- Step 4: Create the Dataset.
- Step 5: Initialize the Model Parameters.
- Step 6: Encoder Class.
- Step 7: Attention Mechanism Class.
- Step 8: Decoder Class.
What is attention distance?
Attention distance was computed as the average distance between the query pixel and the rest of the patch, multiplied by the attention weight. They used 128 example images and averaged their results. An example: if a pixel is 20 pixels away and the attention weight is 0.5 the distance is 10.
What is attention pooling?
An attention pooling layer is used to integrate local representations into the final sentence representation with attention weights.
How does attention work in images?
With an Attention mechanism, the image is first divided into n parts, and we compute an image representation of each When the RNN is generating a new word, the attention mechanism is focusing on the relevant part of the image, so the decoder only uses specific parts of the image.
Are 16 heads really better than one?
It is particularly striking that in a few layers (2, 3 and 10), some heads are sufficient, ie. it is possible to retain the same (or a better) level of performance with only one head. So yes, in some cases, sixteen heads (well, here twelve) are not necessarily better than one.
How do attention heads work?
Multiple Attention Heads In the Transformer, the Attention module repeats its computations multiple times in parallel. Each of these is called an Attention Head. The Attention module splits its Query, Key, and Value parameters N-ways and passes each split independently through a separate Head.
What is Encoder Decoder attention?
Attention is proposed as a solution to the limitation of the Encoder-Decoder model encoding the input sequence to one fixed length vector from which to decode each output time step. This issue is believed to be more of a problem when decoding long sequences.
What is Channel wise attention?
Channel-wise Soft Attention is an attention mechanism in computer vision that assigns “soft” attention weights for each channel . In soft channel-wise attention, the alignment weights are learned and placed “softly” over each channel.