Is Hadoop a big data platform
A distributed file system, a MapReduce programming framework, and an extended family of tools for processing huge data sets on large clusters of commodity hardware, Hadoop has been synonymous with “big data” for more than a decade.
What platform does Hadoop run on?
Original author(s)Doug Cutting, Mike CafarellaWritten inJavaOperating systemCross-platformTypeDistributed file systemLicenseApache License 2.0
Is Hadoop a cloud platform?
Cloud computing where software’s and applications installed in the cloud accessible via the internet, but Hadoop is a Java-based framework used to manipulate data in the cloud or on premises. Hadoop can be installed on cloud servers to manage Big data whereas cloud alone cannot manage data without Hadoop in It.
Is Hadoop platform as a service?
Introducing Genie — the Hadoop Platform as a Service. Amazon provides Hadoop Infrastructure as a Service, via their Elastic MapReduce (EMR) offering. EMR provides an API to provision and run Hadoop clusters (i.e. infrastructure), on which you can run one or more Hadoop jobs.What is the best big data platform?
- Cloudera. …
- Pivotal Big Data Suite. …
- Microsoft Azure HDInsight. …
- SAP HANA. …
- Vertica. …
- Aster Discovery Platform. …
- Oracle Big Data SQL. …
- IBM zEnterprise Analytics System.
What kind of database is Hadoop?
Hadoop is not a type of database, but rather a software ecosystem that allows for massively parallel computing. It is an enabler of certain types NoSQL distributed databases (such as HBase), which can allow for data to be spread across thousands of servers with little reduction in performance.
Why Hadoop is called a big data technology?
Hadoop comes handy when we deal with enormous data. It may not make the process faster, but gives us the capability to use parallel processing capability to handle big data. In short, Hadoop gives us capability to deal with the complexities of high volume, velocity and variety of data (popularly known as 3Vs).
Is Hadoop open source?
Apache Hadoop is an open source software platform for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware.Why Hadoop is called commodity hardware?
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on hardware based on open standards or what is called commodity hardware. This means the system is capable of running different operating systems (OSes) such as Windows or Linux without requiring special drivers.
Is Hadoop PaaS or SAAS?We refer to this as Hadoop-as-a-Service (HaaS), a sub-category of Platform-as-a-Service (PaaS). Running Hadoop as a managed cloud-based service is not a cheap proposition but it does save money over buying large numbers of clusters.
Article first time published onDoes Netflix use Hadoop?
Netflix’s big data infrastructure Netflix uses data processing software and traditional business intelligence tools such as Hadoop and Teradata, as well as its own open-source solutions such as Lipstick and Genie, to gather, store, and process massive amounts of information.
Is Hadoop Java based?
Hadoop is an open source, Java based framework used for storing and processing big data. The data is stored on inexpensive commodity servers that run as clusters. Its distributed file system enables concurrent processing and fault tolerance.
Is Hadoop a prem or cloud?
Now that the term “cloud” has been defined, it’s easy to understand what the jargony phrase “Hadoop in the cloud” means: it is running Hadoop clusters on resources offered by a cloud provider. This practice is normally compared with running Hadoop clusters on your own hardware, called on-premises clusters or “on-prem.”
What is Hadoop in AWS?
Apache Hadoop is an open source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data. Instead of using one large computer to store and process the data, Hadoop allows clustering multiple computers to analyze massive datasets in parallel more quickly.
What is the difference between AWS and Hadoop?
As opposed to AWS EMR, which is a cloud platform, Hadoop is a data storage and analytics program developed by Apache. … In fact, one reason why healthcare facilities may choose to invest in AWS EMR is so that they can access Hadoop data storage and analytics without having to maintain a Hadoop Cluster on their own.
What is an example of a data platform?
For example, an EDP can include OLTP databases, data warehouses, and a data lake. … A Cloud Data Platform (not to be confused with CDP—Customer Data Platform) is a catch-all term for data platforms entirely built with cloud computing technologies and data stores.
What are big data platforms?
Big data platform is a type of IT solution that combines the features and capabilities of several big data application and utilities within a single solution. It is an enterprise class IT platform that enables organization in developing, deploying, operating and managing a big data infrastructure /environment.
Which of the following are big data platform?
Relational databases: Big data platforms include relational database vendors (such as Actian, SAP, Teradata, Oracle, Microsoft, and HP) as well as upstarts (such as Pivotal).
What is difference between big data and Hadoop?
Big Data is treated like an asset, which can be valuable, whereas Hadoop is treated like a program to bring out the value from the asset, which is the main difference between Big Data and Hadoop. Big Data is unsorted and raw, whereas Hadoop is designed to manage and handle complicated and sophisticated Big Data.
What type of technology is Hadoop?
Hadoop is the technology that enabled data scalability in Big Data. It is a free software platform developed in Java language for cluster-oriented distributed computing and processing large volumes of data, with attention to fault tolerance.
Is Hadoop a cluster computing?
A Hadoop cluster is a special type of computational cluster designed specifically for storing and analyzing huge amounts of unstructured data in a distributed computing environment. … Typically one machine in the cluster is designated as the NameNode and another machine the as JobTracker; these are the masters.
What are Hadoop advantages over a traditional platform?
Hadoop is a highly scalable storage platform because it can store and distribute very large data sets across hundreds of inexpensive servers that operate in parallel. Unlike traditional relational database systems (RDBMS) that can’t scale to process large amounts of data.
Is Hadoop structured or unstructured data?
Incompatibly Structured Data (But they call it Unstructured) Hadoop has an abstraction layer called Hive which we use to process this structured data.
What is Hadoop HBase?
HBase is a column-oriented non-relational database management system that runs on top of Hadoop Distributed File System (HDFS). HBase provides a fault-tolerant way of storing sparse data sets, which are common in many big data use cases. … HBase does support writing applications in Apache Avro, REST and Thrift.
Is Hadoop best for live streaming of data?
It is best for real-time streaming of data. 4. It can handle any type of data.
Is Hadoop a distributed framework?
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing. The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
What was the Hadoop named after?
What was Hadoop named after? Explanation: Doug Cutting, Hadoop creator, named the framework after his child’s stuffed toy elephant. Explanation: Apache Hadoop is an open-source software framework for distributed storage and distributed processing of Big Data on clusters of commodity hardware. 8.
What is Hadoop application?
Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs. History. Today’s World.
What is spark vs Hadoop?
Apache Hadoop and Apache Spark are both open-source frameworks for big data processing with some key differences. Hadoop uses the MapReduce to process data, while Spark uses resilient distributed datasets (RDDs).
Is Hadoop distributed computing?
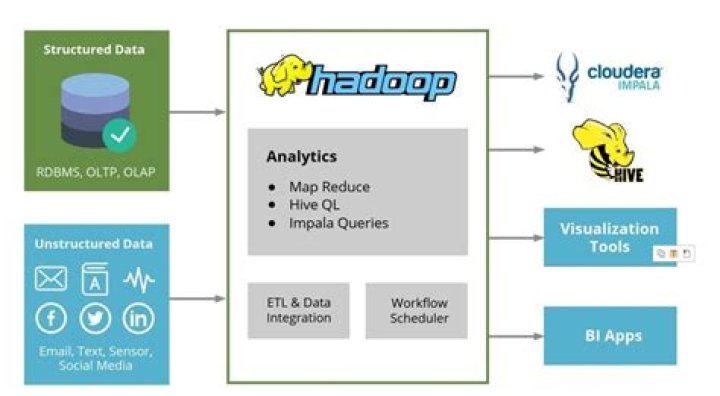
Hadoop is only one of the distributed computing. … Hadoop is an open source framework for writing and running distributed applications with amounts of data. Figure 1 illustrates what Hadoop is. A Hadoop cluster has many parallel machines that store and process big data sets.
Is EMR a PaaS?
Data Platform as a Service (PaaS)—cloud-based offerings like Amazon S3 and Redshift or EMR provide a complete data stack, except for ETL and BI. Data Software as a Service (SaaS)—an end-to-end data stack in one tool.