What are the services of HDFS
Hadoop as a service (HaaS), also known as Hadoop in the cloud, is a big data analytics framework that stores and analyzes data in the cloud using Hadoop. … Hadoop’s storage mechanism, the Hadoop Distributed File System, distributes these workloads across multiple nodes so they can be processed in parallel.
How many Java services are there in Hadoop?
Hadoop 1.0 There were total 4 services NameNode,SecondaryNameNode, DataNode, JobTracker, and TaskTracker. Each service runs on a JVM. 4 JVMs for NameNode,SecondaryNameNode, DataNode, JobTracker each. A TaskTracker is a service in the cluster that accepts tasks – Map, Reduce and Shuffle operations – from a JobTracker.
How many nodes does Hadoop cluster have?
Master Node – Master node in a hadoop cluster is responsible for storing data in HDFS and executing parallel computation the stored data using MapReduce. Master Node has 3 nodes – NameNode, Secondary NameNode and JobTracker.
What are the three main components of a Hadoop cluster?
- Hadoop HDFS – Hadoop Distributed File System (HDFS) is the storage unit of Hadoop.
- Hadoop MapReduce – Hadoop MapReduce is the processing unit of Hadoop.
- Hadoop YARN – Hadoop YARN is a resource management unit of Hadoop.
Is S3 built on HDFS?
HDFS on Ephemeral StorageAmazon S3Read350 mbps/node120 mbps/nodeWrite200 mbps/node100 mbps/node
What is cluster in Hadoop?
A Hadoop cluster is a collection of computers, known as nodes, that are networked together to perform these kinds of parallel computations on big data sets. … Hadoop clusters consist of a network of connected master and slave nodes that utilize high availability, low-cost commodity hardware.
What are the various system roles in HDFS development?
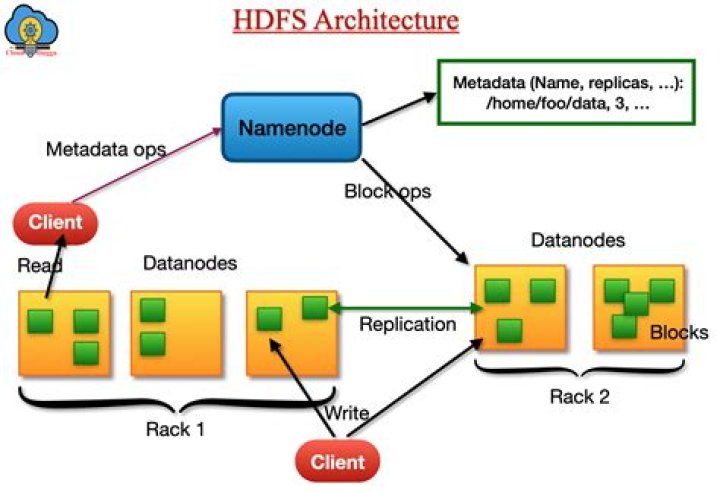
The Hadoop Distributed File System (HDFS) is the primary data storage system used by Hadoop applications. HDFS employs a NameNode and DataNode architecture to implement a distributed file system that provides high-performance access to data across highly scalable Hadoop clusters.
How many different technologies are in the Hadoop ecosystem?
And, although the name has become synonymous with big data technology, in fact, Hadoop now represents a vast system of more than 100 interrelated open source projects. In the wide world of Hadoop today, there are seven technology areas that have garnered a high level of interest.Which of the following has the world's largest Hadoop cluster?
The correct answer is option C (Facebook). Facebook is using Hadoop for data warehousing and they are having the largest Hadoop storage cluster in the world.
What are the 5 Vs of big data?The 5 V’s of big data (velocity, volume, value, variety and veracity) are the five main and innate characteristics of big data.
Article first time published onWhat is namespace and Blockpool?
A Namespace and its block pool together are called Namespace Volume. It is a self-contained unit of management. When a Namenode/namespace is deleted, the corresponding block pool at the Datanodes is deleted. Each namespace volume is upgraded as a unit, during cluster upgrade.
What is multi node Hadoop cluster?
A Multi Node Cluster in Hadoop contains two or more DataNodes in a distributed Hadoop environment. This is practically used in organizations to store and analyze their Petabytes and Exabytes of data. Learning to set up a multi node cluster gears you closer to your much needed Hadoop certification.
How many Hadoop nodes do I need?
Number of Data Nodes Required Data node capacity will be 48 TB. The number of required data nodes is 478/48 ~ 10. In general, the number of data nodes required is Node= DS/(no. of disks in JBOD*diskspace per disk).
How many data nodes can run on a single Hadoop cluster?
you can have 1 Name Node for entire cluster. If u are serious about the performance, then you can configure another Name Node for other set of racks. But 1 Name Node per Rack is not advisable.
How is Hadoop cluster size calculated?
From command line: You view the information about all datanodes and their disk usage in the namenode UI’s Datanodes tab. Total cluster disk space can be seen in the summary part of the main page.
Does EMR use HDFS?
HDFS and EMRFS are the two main file systems used with Amazon EMR. … An advantage of HDFS is data awareness between the Hadoop cluster nodes managing the clusters and the Hadoop cluster nodes managing the individual steps. For more information, see Hadoop documentation . HDFS is used by the master and core nodes.
Does EMR use HDFS or S3?
HDFS and the EMR File System (EMRFS), which uses Amazon S3, are both compatible with Amazon EMR, but they’re not interchangeable.
Is HDFS faster than S3?
8xl (roughly 20MB/s per core). That is to say, on a per node basis, HDFS can yield 6X higher read throughput than S3. Thus, given that the S3 is 10x cheaper than HDFS, we find that S3 is almost 2x better compared to HDFS on performance per dollar.
How many data nodes required in the pipeline for file write in HDFS if the number of replicas is 3?
Suppose the replication factor is 3, so there are three nodes in the pipeline. The DataStreamer streams the packet to the first DataNode in the pipeline, which stores each packet and forwards it to the second node in the pipeline.
What are the three daemons that manage HDFS?
The daemons of HDFS i.e NameNode, DataNode and Secondary NameNode helps to store the huge volume of data and the daemons of MapReduce i.e JobTracker and Task- Tracker helps to process this huge volume of data. All these daemons together makes Hadoop strong for storing and re- trieving the data at anytime.
Who is responsible for replication in Hadoop cluster?
Files in HDFS are write-once and have strictly one writer at any time. The NameNode makes all decisions regarding replication of blocks. It periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster.
How many nodes are in a cluster?
Every cluster has one master node, which is a unified endpoint within the cluster, and at least two worker nodes. All of these nodes communicate with each other through a shared network to perform operations.
What is single node Hadoop cluster?
A single node cluster means only one DataNode running and setting up all the NameNode, DataNode, ResourceManager, and NodeManager on a single machine. This is used for studying and testing purposes.
What is cluster Server and how it works?
Server clustering refers to a group of servers working together on one system to provide users with higher availability. These clusters are used to reduce downtime and outages by allowing another server to take over in an outage event. … A group of servers are connected to a single system.
How many V are there in big data?
Volume, velocity, variety, veracity and value are the five keys to making big data a huge business.
Which has the world's largest head of cluster?
Que.__________ has the world’s largest Hadoop cluster.b.Datamaticsc.Facebookd.None of the mentionedAnswer:Facebook
What is size of big data?
The term Big Data refers to a dataset which is too large or too complex for ordinary computing devices to process. As such, it is relative to the available computing power on the market. If you look at recent history of data, then in 1999 we had a total of 1.5 exabytes of data and 1 gigabyte was considered big data.
Why pig is faster than Hive?
b. Especially, for all the data load related work While you don’t want to create the schema. Since it has many SQL-related functions and additionally you have cogroup function as well. It does support Avro Hadoop file format. Pig is faster than Hive.
What are the clients of HBase?
- The HBase shell.
- Kundera – the object mapper.
- The REST client.
- The Thrift client.
- The Hadoop ecosystem client.
What is the importance and the role of Apache Hive in Hadoop?
Hive allows users to read, write, and manage petabytes of data using SQL. Hive is built on top of Apache Hadoop, which is an open-source framework used to efficiently store and process large datasets. As a result, Hive is closely integrated with Hadoop, and is designed to work quickly on petabytes of data.
What is v3 in big data?
Dubbed the three Vs; volume, velocity, and variety, these are key to understanding how we can measure big data and just how very different ‘big data’ is to old fashioned data. Volume. The most obvious one is where we’ll start.




