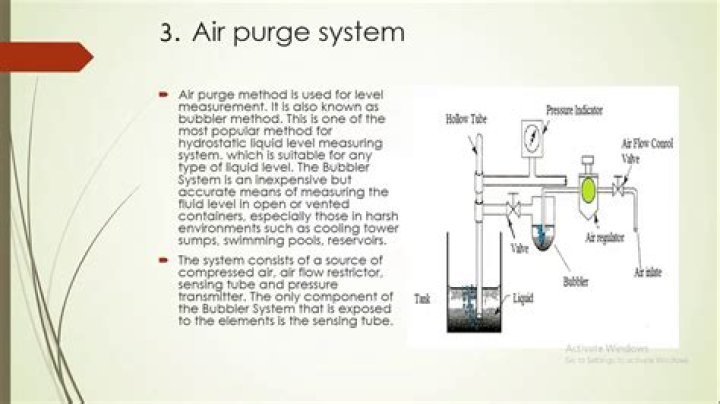
What is a client node in HDFS

Client nodes are in charge of loading the data into the cluster. Client nodes first submit MapReduce jobs describing how data needs to be processed and then fetch the results once the processing is finished.
What is Hadoop example?
Examples of Hadoop Financial services companies use analytics to assess risk, build investment models, and create trading algorithms; Hadoop has been used to help build and run those applications. … For example, they can use Hadoop-powered analytics to execute predictive maintenance on their infrastructure.
What is Hadoop in simple terms?
Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs.
What is Hadoop software used for?
Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs.What is the difference between a client node and a name node in HDFS?
The main difference between NameNode and DataNode in Hadoop is that the NameNode is the master node in HDFS that manages the file system metadata while the DataNode is a slave node in HDFS that stores the actual data as instructed by the NameNode. In brief, NameNode controls and manages a single or multiple data nodes.
How do I start Hadoop?
- start-all.sh & stop-all.sh. Used to start and stop Hadoop daemons all at once. …
- start-dfs.sh, stop-dfs.sh and start-yarn.sh, stop-yarn.sh. …
- hadoop-daemon.sh namenode/datanode and yarn-deamon.sh resourcemanager. …
- Note : You should have ssh enabled if you want to start all the daemons on all the nodes from one machine.
What is Hadoop DFS?
The Hadoop Distributed File System (HDFS) is the primary data storage system used by Hadoop applications. HDFS employs a NameNode and DataNode architecture to implement a distributed file system that provides high-performance access to data across highly scalable Hadoop clusters.
Why Hadoop is used in big data?
Hadoop was developed because it represented the most pragmatic way to allow companies to manage huge volumes of data easily. Hadoop allowed big problems to be broken down into smaller elements so that analysis could be done quickly and cost-effectively.What are Hadoop products?
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data. Hadoop YARN: A framework for job scheduling and cluster resource management. Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
What kind of database is Hadoop?Hadoop is not a type of database, but rather a software ecosystem that allows for massively parallel computing. It is an enabler of certain types NoSQL distributed databases (such as HBase), which can allow for data to be spread across thousands of servers with little reduction in performance.
Article first time published onHow big data problems are handled by Hadoop?
It can handle arbitrary text and binary data. So Hadoop can digest any unstructured data easily. We saw how having separate storage and processing clusters is not the best fit for big data. Hadoop clusters, however, provide storage and distributed computing all in one.
What is difference between Hadoop and big data?
Big Data is treated like an asset, which can be valuable, whereas Hadoop is treated like a program to bring out the value from the asset, which is the main difference between Big Data and Hadoop. Big Data is unsorted and raw, whereas Hadoop is designed to manage and handle complicated and sophisticated Big Data.
How many nodes of Hadoop did you Yahoo test?
In 2007, Yahoo successfully tested Hadoop on a 1000 node cluster and start using it.
Is S3 based on HDFS?
HDFS and the EMR File System (EMRFS), which uses Amazon S3, are both compatible with Amazon EMR, but they’re not interchangeable. HDFS is an implementation of the Hadoop FileSystem API, which models POSIX file system behavior. EMRFS is an object store, not a file system.
What is the difference between TaskTracker and JobTracker?
TaskTrackers will be assigned Mapper and Reducer tasks to execute by JobTracker. TaskTracker failure is not considered fatal. When a TaskTracker becomes unresponsive, JobTracker will assign the task executed by the TaskTracker to another node.
What is Apache spark?
Apache Spark is an open-source, distributed processing system used for big data workloads. It utilizes in-memory caching and optimized query execution for fast queries against data of any size. Simply put, Spark is a fast and general engine for large-scale data processing.
What is spark vs Hadoop?
Apache Hadoop and Apache Spark are both open-source frameworks for big data processing with some key differences. Hadoop uses the MapReduce to process data, while Spark uses resilient distributed datasets (RDDs).
What is difference between Hadoop and HDFS?
The main difference between Hadoop and HDFS is that the Hadoop is an open source framework that helps to store, process and analyze a large volume of data while the HDFS is the distributed file system of Hadoop that provides high throughput access to application data. In brief, HDFS is a module in Hadoop.
Can I install Hadoop on Windows?
Hadoop Installation on Windows 10 To install Hadoop, you should have Java version 1.8 in your system.
Where is Hadoop installed?
Navigate to the path where hadoop is installed. locate ${HADOOP_HOME}/etc/hadoop , e.g. When you type the ls for this folder you should see all these files. Core configuration settings are available in hadoop-env.sh.
How do I know if Hadoop is running?
To check Hadoop daemons are running or not, what you can do is just run the jps command in the shell. You just have to type ‘jps’ (make sure JDK is installed in your system). It lists all the running java processes and will list out the Hadoop daemons that are running.
What is Hadoop and what are its basic components?
There are three components of Hadoop: Hadoop HDFS – Hadoop Distributed File System (HDFS) is the storage unit. Hadoop MapReduce – Hadoop MapReduce is the processing unit. Hadoop YARN – Yet Another Resource Negotiator (YARN) is a resource management unit.
What is Hadoop what are its components?
There are four major elements of Hadoop i.e. HDFS, MapReduce, YARN, and Hadoop Common. … Following are the components that collectively form a Hadoop ecosystem: HDFS: Hadoop Distributed File System. YARN: Yet Another Resource Negotiator. MapReduce: Programming based Data Processing.
What are the features of Hadoop?
- Open Source: Hadoop is open-source, which means it is free to use. …
- Highly Scalable Cluster: Hadoop is a highly scalable model. …
- Fault Tolerance is Available: …
- High Availability is Provided: …
- Cost-Effective: …
- Hadoop Provide Flexibility: …
- Easy to Use: …
- Hadoop uses Data Locality:
Does Hadoop have database?
Is Hadoop a Database? Hadoop is not a database, but rather an open-source software framework specifically built to handle large volumes of structured and semi-structured data.
What is difference between big data and database?
Big Data is a term applied to data sets whose size or type is beyond the ability of traditional relational databases. … There can be any varieties of data while DB can be defined through some schema. It is difficult to store and process while Databases like SQL, data can be easily stored and process.
What is the difference between relational database and Hadoop?
The key difference between RDBMS and Hadoop is that the RDBMS stores structured data while the Hadoop stores structured, semi-structured, and unstructured data. The RDBMS is a database management system based on the relational model.
What are the 5 Vs of big data?
The 5 V’s of big data (velocity, volume, value, variety and veracity) are the five main and innate characteristics of big data.
Who owns Hadoop?
Original author(s)Doug Cutting, Mike CafarellaDeveloper(s)Apache Software FoundationInitial releaseApril 1, 2006
What is Hadoop Slideshare?
Hadoop is a framework for running applications on large clusters built of commodity hardware. —-HADOOP WIKI Hadoop is a free, Java-based programming framework that supports the processing of large data sets in a distributed computing environment.