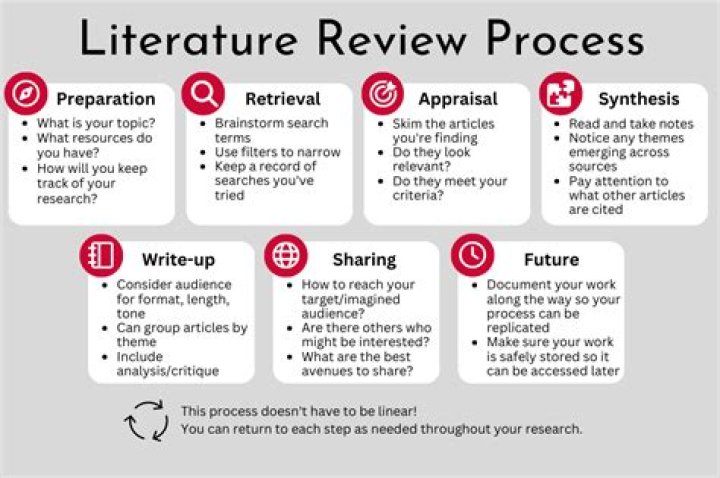
What is naive Bayes technique
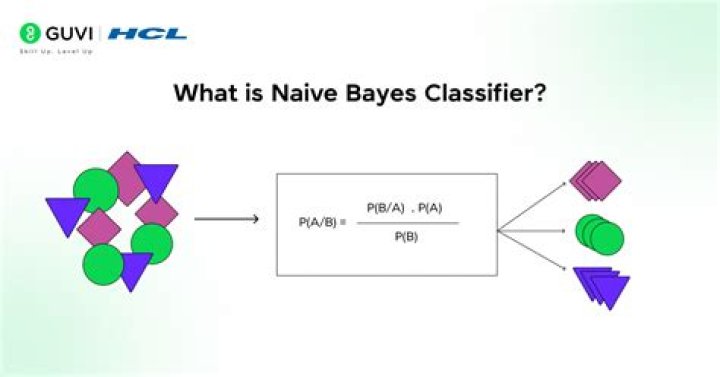
What is Naive Bayes algorithm? It is a classification technique based on Bayes’ Theorem with an assumption of independence among predictors. In simple terms, a Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature.
Why is naive Bayes used?
Naïve Bayes is one of the fast and easy ML algorithms to predict a class of datasets. It can be used for Binary as well as Multi-class Classifications. It performs well in Multi-class predictions as compared to the other Algorithms. It is the most popular choice for text classification problems.
What is naive Bayes probability?
Naive Bayes classifier assume that the effect of the value of a predictor (x) on a given class (c) is independent of the values of other predictors. This assumption is called class conditional independence. P(c|x) is the posterior probability of class (target) given predictor (attribute).
What is the main idea of naive Bayesian classification?
A naive Bayes classifier assumes that the presence (or absence) of a particular feature of a class is unrelated to the presence (or absence) of any other feature, given the class variable. Basically, it’s “naive” because it makes assumptions that may or may not turn out to be correct.Is naive Bayes supervised or unsupervised?
Naive Bayes classification is a form of supervised learning. It is considered to be supervised since naive Bayes classifiers are trained using labeled data, ie. … This contrasts with unsupervised learning, where there is no pre-labeled data available.
Is Naive Bayes machine learning?
Naive Bayes is a machine learning model that is used for large volumes of data, even if you are working with data that has millions of data records the recommended approach is Naive Bayes. It gives very good results when it comes to NLP tasks such as sentimental analysis.
Is naive Bayes classification or regression?
Naïve Bayes is a classification method based on Bayes’ theorem that derives the probability of the given feature vector being associated with a label. … Logistic regression is a linear classification method that learns the probability of a sample belonging to a certain class.
What Gaussian Naive Bayes?
Gaussian Naive Bayes is a variant of Naive Bayes that follows Gaussian normal distribution and supports continuous data. … Naive Bayes are a group of supervised machine learning classification algorithms based on the Bayes theorem. It is a simple classification technique, but has high functionality.What type of learning is classification?
In machine learning, classification is a supervised learning concept which basically categorizes a set of data into classes. The most common classification problems are – speech recognition, face detection, handwriting recognition, document classification, etc.
What are the differences between naive Bayesian classifier and Bayesian belief network?Naive Bayes assumes conditional independence, P(X|Y,Z)=P(X|Z), Whereas more general Bayes Nets (sometimes called Bayesian Belief Networks) will allow the user to specify which attributes are, in fact, conditionally independent.
Article first time published onIs naive Bayes Linear?
Naive Bayes is a linear classifier.
Why is naive Bayes good for text classification?
As the Naive Bayes algorithm has the assumption of the “Naive” features it performs much better than other algorithms like Logistic Regression, Tree based algorithms etc. The Naive Bayes classifier is much faster with its probability calculations.
What is Naive Bayes classifier in data mining?
Naive Bayes classifiers are a collection of classification algorithms based on Bayes’ Theorem. It is not a single algorithm but a family of algorithms where all of them share a common principle, i.e. every pair of features being classified is independent of each other.
What is SVM in deep learning?
“Support Vector Machine” (SVM) is a supervised machine learning algorithm that can be used for both classification or regression challenges. … Support Vectors are simply the coordinates of individual observation. The SVM classifier is a frontier that best segregates the two classes (hyper-plane/ line).
Which is better logistic regression or naive Bayes?
Naive Bayes also assumes that the features are conditionally independent. … In short Naive Bayes has a higher bias but lower variance compared to logistic regression. If the data set follows the bias then Naive Bayes will be a better classifier.
What is better than naive Bayes?
Decision trees work better with lots of data compared to Naive Bayes. Naive Bayes is used a lot in robotics and computer vision, and does quite well with those tasks. Decision trees perform very poorly in those situations.
What is decision tree in ML?
Introduction Decision Trees are a type of Supervised Machine Learning (that is you explain what the input is and what the corresponding output is in the training data) where the data is continuously split according to a certain parameter. The tree can be explained by two entities, namely decision nodes and leaves.
What is lazy learning algorithm?
From Wikipedia, the free encyclopedia. In machine learning, lazy learning is a learning method in which generalization of the training data is, in theory, delayed until a query is made to the system, as opposed to eager learning, where the system tries to generalize the training data before receiving queries.
Why K NN is called a lazy learner?
KNN algorithm is the Classification algorithm. It is also called as K Nearest Neighbor Classifier. K-NN is a lazy learner because it doesn’t learn a discriminative function from the training data but memorizes the training dataset instead. … A lazy learner does not have a training phase.
What is the difference between supervised & unsupervised learning?
The main difference between supervised and unsupervised learning: Labeled data. The main distinction between the two approaches is the use of labeled datasets. To put it simply, supervised learning uses labeled input and output data, while an unsupervised learning algorithm does not.
Is naive Bayes parametric?
Therefore, naive Bayes can be either parametric or nonparametric, although in practice the former is more common. In machine learning we are often interested in a function of the distribution T(F), for example, the mean.
What is the difference between naive Bayes and Gaussian naive Bayes?
Naive Bayes has higher accuracy and speed when we have large data points. There are three types of Naive Bayes models: Gaussian, Multinomial, and Bernoulli. Gaussian Naive Bayes – This is a variant of Naive Bayes which supports continuous values and has an assumption that each class is normally distributed.
Why is the naive Bayes method called that what is naive about it and what is Bayesian about it?
Naive Bayes is called naive because it assumes that each input variable is independent. … The thought behind naive Bayes classification is to try to classify the data by maximizing P(O | Ci)P(Ci) using Bayes theorem of posterior probability (where O is the Object or tuple in a dataset and “i” is an index of the class).
Is naive Bayes Bayesian?
In the statistics and computer science literature, naive Bayes models are known under a variety of names, including simple Bayes and independence Bayes. All these names reference the use of Bayes’ theorem in the classifier’s decision rule, but naïve Bayes is not (necessarily) a Bayesian method.
Why Bayes classifier is optimal?
It can be shown that of all classifiers, the Optimal Bayes classifier is the one that will have the lowest probability of miss classifying an observation, i.e. the lowest probability of error. … So if we know the posterior distribution, then using the Bayes classifier is as good as it gets.
Is K nearest neighbor linear?
K Nearest Neighbor is one of the simplest method for classification as well as regression problem. That is the reason it is widely adopted. KNN is a supervised method that uses estimation based on values of neighbors. … The approach is made for linear as well as nonlinear regression problem.
What are the different classifiers in machine learning?
There are perhaps four main types of classification tasks that you may encounter; they are: Binary Classification. Multi-Class Classification. Multi-Label Classification.
Is Naive Bayes good for sentiment analysis?
In various applications such as spam filtering, text classification, sentiment analysis, and recommendation systems, Naive Bayes classifier is used successfully. … When used for textual data analysis, such as Natural Language Processing, the Naive Bayes classification yields good results.
How is Naive Bayes algorithm useful for learning and classifying?
Since a Naive Bayes text classifier is based on the Bayes’s Theorem, which helps us compute the conditional probabilities of occurrence of two events based on the probabilities of occurrence of each individual event, encoding those probabilities is extremely useful.