Where can I find hive site XML
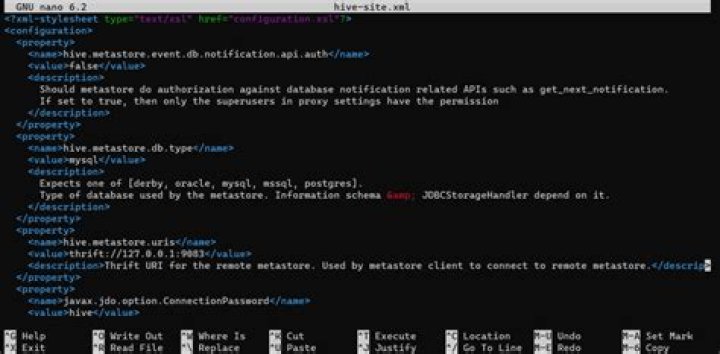
You can find hive-site. xml in /etc/hive/conf/, but if you’re using Ambari to manage your cluster then do the modification in Ambari so it can deploy it to every host.
Where is Hdfs site xml located?
xml. store files, located under $HADOOP_HOME/conf, are used to configure high availability (HA) for the HDFS NameNode within the MapReduce framework in Platform Symphony.
Where is Hive-site xml located in cloudera?
If the components are manually installed using Cloudera parcels and if you want to override any configuration property, use the corresponding configuration file under /etc/<component>/conf/ . There used to be a file called hive-default. xml.
What is Hive-site xml?
The hive-site.xml is the global hive configuration file. The file hive-default. xml. template contains the default values.What is Mapred site xml?
xml. Lists the parameters for MapReduce configuration. MapReduce is a type of application that can run on the Hadoop 2. This file contains configuration information that overrides the default values for MapReduce parameters. …
Where is HDFS replication controlled?
You can check the replication factor from the hdfs-site. xml fie from conf/ directory of the Hadoop installation directory. hdfs-site. xml configuration file is used to control the HDFS replication factor.
What are the roles of the files core-site xml and HDFS-site xml?
The core-site. xml file informs Hadoop daemon where NameNode runs in the cluster. It contains the configuration settings for Hadoop Core such as I/O settings that are common to HDFS and MapReduce. The hdfs-site.
How do I start a Hive Derby database?
- Download Derby.
- Set Environment.
- Starting Derby.
- Configure Hive to Use Network Derby.
- Copy Derby Jar Files.
- Start Up Hive.
- The Result.
What is Hive Metastore Uris?
metastore. uris is a comma separated list of metastore URIs on which a metastore service is running. After restarting the Hive services, the value for hive.metastore.uris shows the new Hive metastore service, along with the already configured values: thrift://abc1209.abc.com:9083,thrift://abc1210.abc.com:9083.
In which file Metastore of Hive can be configured?In server-specific configuration files (supported starting Hive 0.14). You can set metastore-specific configuration values in hivemetastore-site. xml, and HiveServer2-specific configuration values in hiveserver2-site.
Article first time published onWhat is hive server2 enable DOAS?
The authentication that the server is set to use. Set the value to true. When the value is set to true, the user who makes calls to the server can also perform Hive operations on the server.
How do I change Metastore in hive?
- To Maintain a single copy of Embedded Metastore:
- Configuring Local Metastore:
- Start Hive CLI service:
- Start Hive Thrift server:
- Start Hive Metastore service:
- Configure Remote Metastore:
Where can I find yarn site xml?
YARN configuration options are stored in the /opt/mapr/hadoop/hadoop-2. x.x/etc/hadoop/yarn-site. xml file and are editable by the root user. This file contains configuration information that overrides the default values for YARN parameters.
Which property configuration is done in Mapred-site xml?
4) MAPRED-SITE. XML->>It is one of the important configuration files which is required for runtime environment settings of a Hadoop. It contains the configuration settings for MapReduce . In this file, we specify a framework name for MapReduce, by setting the MapReduce.framework.name.
What is FS defaultFS?
The fs. defaultFS makes HDFS a file abstraction over a cluster, so that its root is not the same as the local system’s. You need to change the value in order to create the distributed file system.
What kind of scaling does HDFS support?
HDFS was designed as a scalable distributed file system to support thousands of nodes within a single cluster. With enough hardware, scaling to over 100 petabytes of raw storage capacity in one cluster can be easily—and quickly—achieved.
What is Hadoop DFS?
The Hadoop Distributed File System (HDFS) is the primary data storage system used by Hadoop applications. HDFS employs a NameNode and DataNode architecture to implement a distributed file system that provides high-performance access to data across highly scalable Hadoop clusters.
What are the different type of xml files in Hadoop?
- Answer: The different configuration files in Hadoop are –
- core-site. …
- mapred-site.xml — This configuration file specifies a framework name for MapReduce by setting mapreduce.framework.name.
- hdfs-site. …
- yarn-site.
Why HDFS blocks are replicated?
Data Replication. HDFS is designed to reliably store very large files across machines in a large cluster. It stores each file as a sequence of blocks; all blocks in a file except the last block are the same size. The blocks of a file are replicated for fault tolerance.
What is replication factor HDFS?
What Is Replication Factor? Replication factor dictates how many copies of a block should be kept in your cluster. The replication factor is 3 by default and hence any file you create in HDFS will have a replication factor of 3 and each block from the file will be copied to 3 different nodes in your cluster.
What is replication factor Kafka?
Replication factor defines the number of copies of a topic in a Kafka cluster. … Replicas are distributed evenly among Kafka brokers in a cluster.
Where is Hive metadata stored?
Finally the location of the metastore for hive is by default located here /usr/hive/warehouse .
Where is Hive Metastore located?
By default, the location of warehouse is file:///user/hive/warehouse and we can also use hive-site. xml file for local or remote metastore.
How do I access Metastore Hive?
You can query the metastore schema in your MySQL database. Something like: mysql> select * from TBLS; More details on how to configure a MySQL metastore to store metadata for Hive and verify and see the stored metadata here.
How do I run hive on Windows 10?
- Prerequisites. Hardware Requirement. …
- Unzip and Install Hive. After Downloading the Hive, we need to Unzip the apache-hive-3.1. …
- Setting Up Environment Variables. Another important step in setting up a work environment is to set your Systems environment variable. …
- Editing Hive. …
- Starting Hive. …
- Common Issues. …
- Congratulations..!!!!
How do I connect to hive Derby?
- PREREQUISITES: …
- Configure hive with Hadoop edit the hive-env.sh file, which is placed in the $HIVE_HOME/conf directory. …
- Get into conf directory under apache-hive-2.1.1-bin folder and rename hive-default.xml.template to hive-site.xml. …
- Here we are creating metastore_db derby database.
What is limitation of hive built in Derby SQL Server?
Thus both metastore service and hive service runs in the same JVM by using embedded Derby Database. But, this mode also has limitation that, as only one embedded Derby database can access the database files on disk at any one time, so only one Hive session could be open at a time.
What is bucketing in Hive with example?
Bucketing in hive is the concept of breaking data down into ranges, which are known as buckets, to give extra structure to the data so it may be used for more efficient queries. The range for a bucket is determined by the hash value of one or more columns in the dataset (or Hive metastore table).
How do I write Hive-site xml Metastore MySQL?
- i. Install MySQL. [php]$sudo apt-get install mysql-server[/php]
- ii. Copy MySQL connector to lib directory. Download MySQL connector (mysql-connector-java-5.1.35-bin.jar) and copy it into the $HIVE_HOME/lib directory. …
- iii. Edit / Create configuration file hive-site. xml.
Why do we use Hive?
Hive allows users to read, write, and manage petabytes of data using SQL. Hive is built on top of Apache Hadoop, which is an open-source framework used to efficiently store and process large datasets. As a result, Hive is closely integrated with Hadoop, and is designed to work quickly on petabytes of data.
What is Hive user impersonation?
User impersonation enables Hive to submit jobs as a particular user. Without impersonation, Hive submits queries and hadoop commands as the user that started HiveServer2 and Hive Metastore. On a MapR cluster, this user is typically the mapr user or the user specified in the MAPR_USER environment variable.